Convolutional neural networks (CNNs) make decisions using complex feature hierarchies. It is difficult to unveil these using methods like occlusion, SHAP and Grad-CAM as they focus on regions of important pixels. Guided Backpropagation (GBP) addresses this by visualising the specific features that contribute to a model’s output [1]. It does this by modifying the standard backpropagation process to pass only positive gradients that contribute to a prediction.
We explore three ways to compute and interpret GBP gradients. These are the gradients of a:
- Target logit w.r.t. the input \( ( \frac{\partial y_c}{\partial X} )\) – this helps identify which features in the image contribute most to a prediction.
- Target logit w.r.t. the intermediate feature maps \(( \frac{\partial y_c}{\partial A} ) \) – this helps us understand the role of different layers in the network.
- Element in a feature map w.r.t. the input \(( \frac{\partial A_{ij}}{\partial X} )\) – this reveals the spatial properties of abstract features learned by deeper network layers.
Each of these approaches offers unique benefits to interpreting a model. As we go, they will also provide an intuitive understanding of how CNNs work and how methods like Grad-CAM can use the spatial nature of feature maps.
To implement these methods, we will use PyTorch hooks. As you will see, these allow us to extract gradients and activations dynamically during forward and backward passes. By the end, you will have a practical understanding of guided backpropagation and how to interpret its gradients.
Before you get stuck into the article, here is the video version of the lesson. There is another one in the Python section.
A note on terminology
Before we start, let's clarify a few terms:
- Activations are the output from any layer in the network during a forward pass. For example, the raw values from convolutional layers or after those values have been passed into an activation function.
- Similarly, a feature map is one channel in the output of a convolutional layer or after that layer has been passed to an activation function.
- An element is one unit/pixel in a feature map.
We can talk about activated feature maps if they have been activated by a forward pass. However, we can also refer to them simply as feature maps. Whether they are activated or not should be clear from the context.
The theory behind Guided Backpropagation
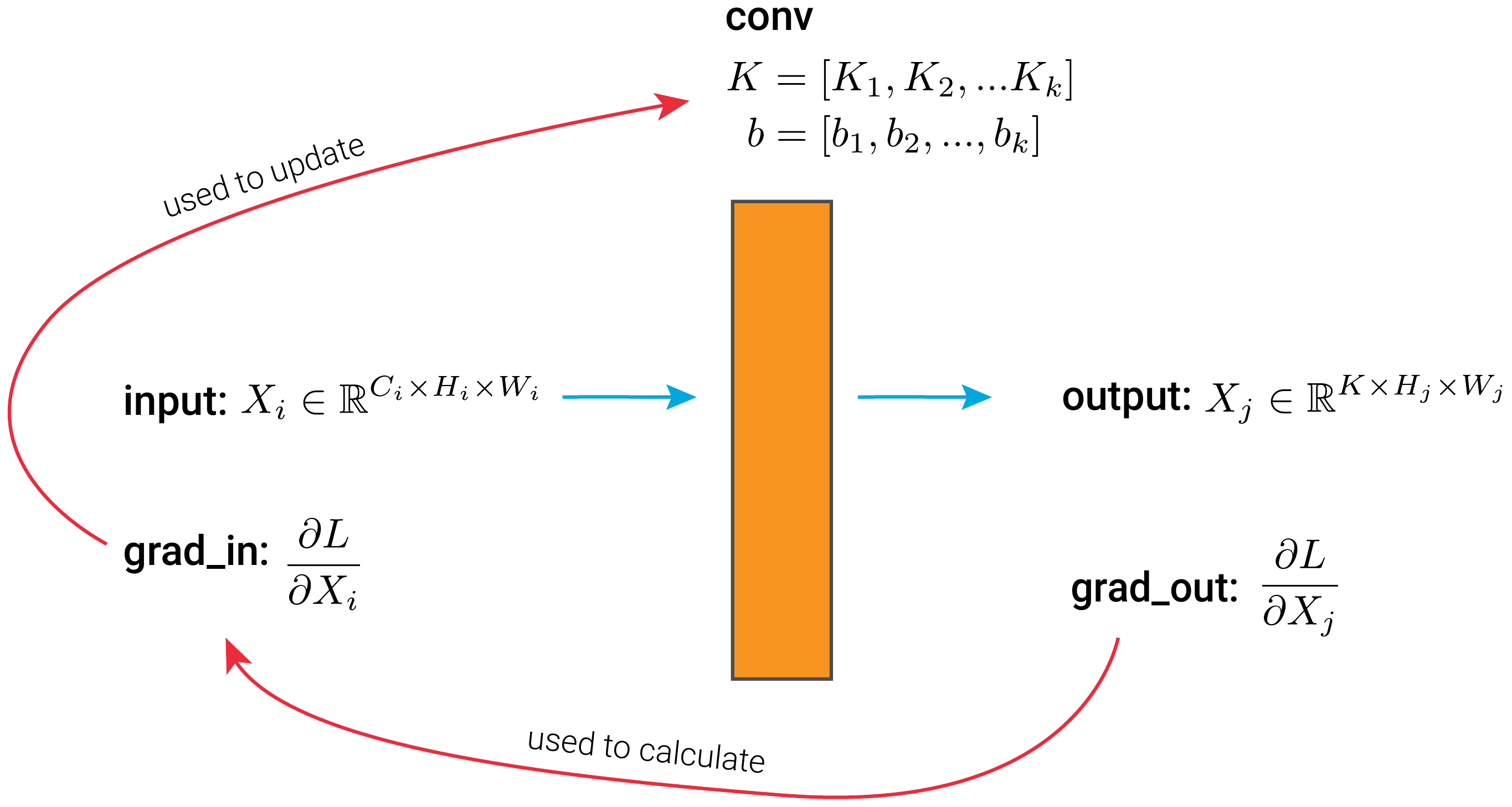
To understand GBP, we start with the standard backpropagation procedure for a convolutional layer seen in Figure 1. This consists of a set of kernels, \(K\), and biases, \(b\). The other parts are the:
- input - set of feature maps or image
- output - set of feature maps
- grad_in is the gradient of the loss w.r.t. the layer's input.
- grad_out is the gradient of the loss w.r.t. the layer's output.
We have labelled these using the same variable names as the hook functions that we apply later. This should help connect the theory to the practical application.
During the forward pass, the layer will apply the kernels and biases to the input to produce a new set of feature maps as output. Without going into detail, during the backward pass, grad_out is passed from the next layer in the network. We use this to help calculate grad_in. grad_in is then used to help update the current layer's kernels and biases.
For GBP, we are not concerned with the final step (i.e. updating the parameters). We only want to visualise the gradients flowing through the network for one input image. When doing this, we make one adjustment to standard backpropagation. That is to only allow positive gradients to flow through ReLU activation layers. A process called ReLU masking.
ReLU masking
To understand ReLU masking, we need to introduce the concept of a guidance signal. This is anything that helps reduce noise in a saliency map or guides the visualization toward features that contribute to the model’s prediction.
With standard backpropagation, ReLU layers already introduce one guidance signal. That is if the activation from the forward pass is zero or less, the gradient from the backwards pass is set to zero. ReLU masking adds an additional guidance signal. That is, if the gradient flowing backwards is negative, it is set to zero.
Looking at Figure 2, you can see the process for standard backpropagation for a ReLU activation layer. During the forward pass, the input is feature maps from the previous convolutional layer. The output will be those same feature maps but with all negative values set to zero.
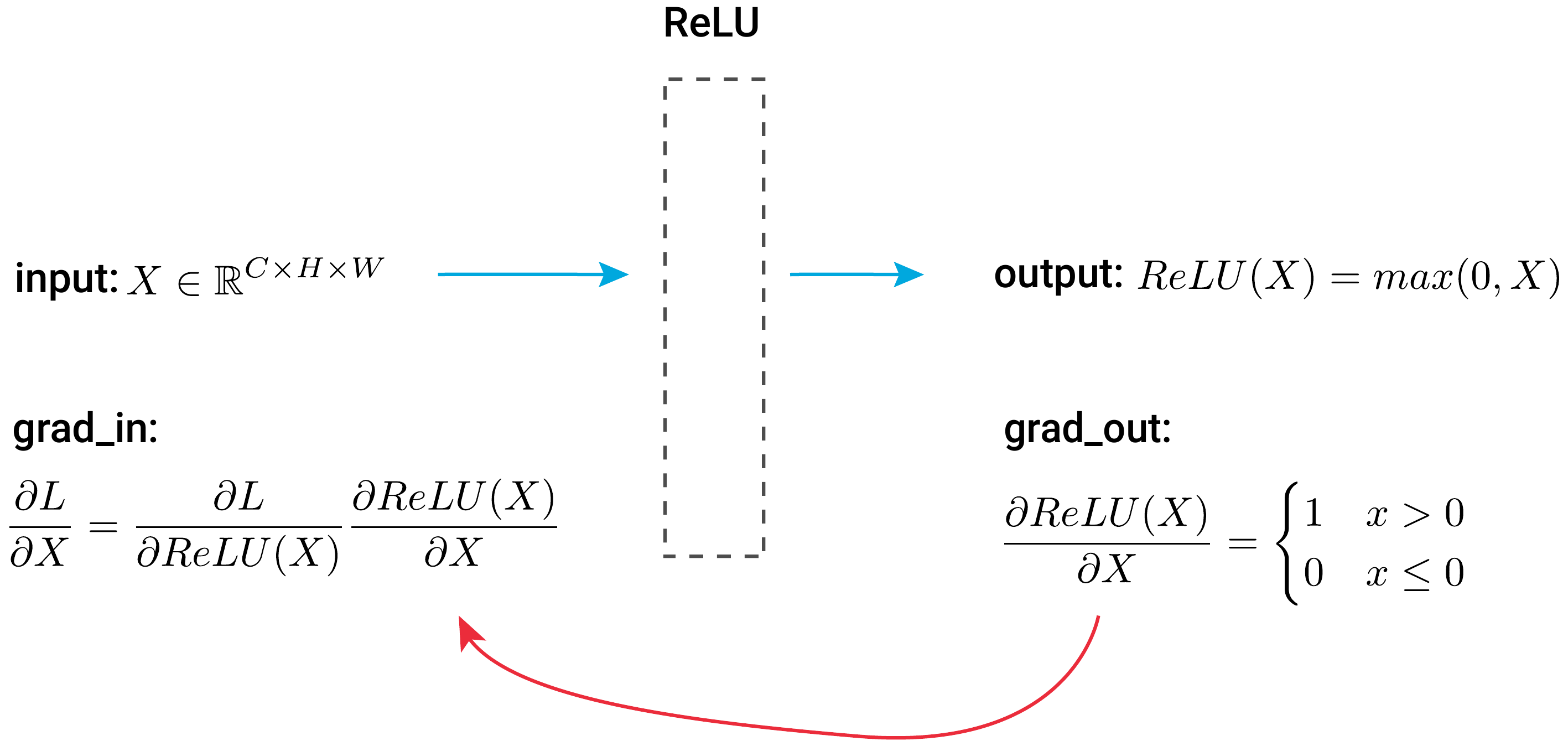
Using the chain rule, we can express grad_in as:
\[
\frac{\partial L}{\partial X} = \frac{\partial L}{\partial \text{ReLU}(X) } \cdot \frac{\partial \text{ReLU}(X) }{\partial X}
\]
The derivative of the ReLU function can be simplified to:
\[
\frac{\partial \text{ReLU}(X) }{\partial X} =
= \mathbb{1}(X > 0)
\]
This is the guidance signal from standard backpropagation. We only pass gradients through ReLU activation functions where the input is positive. Keep in mind that this does not mean we only pass positive gradients. This is because \(\frac{\partial L}{\partial \text{ReLU}(X) }\) can be both positive and negative regardless of whether the elements of the input feature maps are positive or negative.
\[
\frac{\partial L}{\partial X} =
\frac{\partial L}{\partial \text{ReLU}(X) } \cdot \mathbb{1}(X > 0)
\]
So, with guided backpropagation, we introduce an additional guidance signal, \(\mathbb{1}( \frac{\partial L}{\partial \text{ReLU}(X) } > 0 )\). This will set all negative gradients to 0. These modified gradients are then propagated through the network.
\[
\frac{\partial L}{\partial X} = \frac{\partial L}{\partial \text{ReLU}(X) } \cdot \mathbb{1}( \frac{\partial L}{\partial \text{ReLU}(X) } > 0 ) \cdot \mathbb{1}(X > 0)
\]
Like with vanilla gradients, we are typically not interested in \(\frac{\partial L}{\partial X}\) but \(\frac{\partial y_c}{\partial X}\). That is the gradients of an output logit for a given class \(c\) (usually, the class with the highest logit). So, again, we usually start the backwards pass from this logit.
To summarise, GBP works by modifying the ReLU activation functions in a CNN so that all negative gradients are set to 0. These layers will now suppress gradients passed during back propagation in two ways, those where the:
- input is negative (standard backprop)
- gradient is negative (guided backprop)
Now, let's try to understand why this trick works so well.
The intuition behind Guided Backpropagation
In the paper that presented the method, the researchers compare GBP to standard backpropagation and deconvolution — two alternative approaches for creating similar saliency maps. They observed that the method produced "cleaner visualisations" [1]. The intuition for this can also be found in the paper:
We call this method guided backpropagation, because it adds an additional guidance signal from the higher layers to usual backpropagation. This prevents backward flow of negative gradients, corresponding to the neurons which decrease the activation of the higher layer unit we aim to visualize.
As discussed, standard backpropagation already has one guidance signal. That is, gradients are only propagated through ReLU units where the activation is positive in the forward pass. This reduces the number of irrelevant gradients as we only pass those for elements that have increased the activations of neurons in the next layer.
However, we will still pass negative gradients. In standard backpropagation, negative gradients play a crucial role in reducing the activation of elements that are not associated with the target class. When it comes to GBP, we are only interested in visualising elements that are associated with the target class. So, by suppressing negative gradients, we can reduce noise and create cleaner visualisations.
The limitations of Guided Backpropagation
Intuitively, this makes sense. However, we must be aware that the method is still a heuristic and their research lacks a solid mathematical justification for why their method produces faithful and reliable saliency maps. Their empirical evidence of demonstrating clearer visualisations should raise alarm bells about potential human bias. Are we not simply selecting the method based on what looks good to us?
In fact, additional research has shown that GBP is essentially doing partial image recovery [2]. This suggests that the saliency maps may reflect input structure rather than model decisions. We also discussed how model dependence tests suggested that the method only depends on the model's structure and not on its learned parameters [3]. However, a reframing of the tasks used for that test changed this result [4]. Model dependence tests can be seen as a minimal requirement of faithfulness, and the latter result means the evidence that GBP fails these tests is not conclusive.
It is also worth emphasising that GBP is not class-discriminative. For example, fur may be an important feature when classifying images of cats. However, if multiple animals with fur are present in the image, GBP may highlight all fur regions, regardless of which animal they belong to. In other words, GBP highlights features that contribute to the activation of the target class, but not exclusively features that are specific to that class.
Applying Guided Backpropagation with PyTorch hooks
We start the application of GBP, where we ended Vanilla Gradients. That is we use the same imports, model and sample image. We also make use of the process_grads function. You will notice that we have no package for GBP. If you do want to use a package, check out Captum - Guided Backprop. Keep in mind, that the implementation only allows you to visualise gradients w.r.t. the input image and not intermediate layers.
In the previous section, we displayed the model summary seen below. For GBP, the names you see are important. Later, we will use them to reference specific layers in the network and display their gradients. For example, features.5 is the name of the 3rd convolutional layer.
VGG(
(features): Sequential(
(0): Conv2d(3, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(1): ReLU(inplace=True)
(2): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(3): ReLU(inplace=True)
(4): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
(5): Conv2d(64, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(6): ReLU(inplace=True)
(7): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(8): ReLU(inplace=True)
(9): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
(10): Conv2d(128, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
.
.
.Using PyTorch hooks
To implement GBP, we will use PyTorch hooks to change how gradients flow through the network. We also use them to save gradients from intermediate layers. In a later section, we will use them to save activations from intermediate layers. Before that, we must replace the ReLU activation functions in the network.
Our VGG16 network has been created using ReLU with inplace=True. These modify tensors in memory, so the original values are lost. That is, tensors used as input are overwritten by the activation. This can lead to problems when applying hooks, as we may need the original input. While PyTorch allows registering hooks on in-place operations, it may cause runtime errors during backpropagation because the computational graph expects unmodified activations for gradient computation.
We use the code below to replace all ReLU activations with inplace=False ones. This will not impact the output of the model, but it will increase its memory usage. It is important to apply this code before registering any hooks on the ReLU functions. Otherwise, the hooks will be removed.
# Replace all in-place ReLU activations with out-of-place ones
def replace_relu(model):
for name, child in model.named_children():
if isinstance(child, torch.nn.ReLU):
setattr(model, name, torch.nn.ReLU(inplace=False))
print(f"Replacing ReLU activation in layer: {name}")
else:
replace_relu(child) # Recursively apply to submodules
# Apply the modification to the VGG16 model
replace_relu(model)The hook below will be applied to the ReLU functions in the network. By default, all backwards hook functions will have three parameters:
- module the different components or layers of a neural network.
- grad_in: the gradients of the input into the module
- grad_out: the gradients of the output of the module
We also have an additional parameter, layer_name, which is the name of the module. These will be the same as those we saw in the model summary above.
Going back to Figures 1 andFigure 2, it is grad_in that is passed to the previous layer in the network during the backward pass. This is why we modify grad_in with the ReLU_hook function (line 17-21). We do this by replacing all negative gradients with a value of 0 (line 19) and keeping any empty gradients (line 21). Finally, we return the modified gradients (line 26). This will be the new grad_in pass to previous layers. It must be formatted as a tuple for cases where the layer has multiple inputs.
The code will also store the modified gradients (line 24). These will be used when we visualise the gradients of intermediate layers. We detach these from the computational graph so that visualising them does not impact the network (line 24). These gradients will be stored in the gradients dictionary (line 2) with the layer's name as the key (line 24).
# Dictionary to store gradients
gradients = {}
def relu_hook(module, grad_in, grad_out, layer_name):
"""
Guided Backpropagation Hook: Allows only positive gradients to backpropagate.
Parameters:
module (nn.Module): The module where the hook is applied.
grad_in (tuple of Tensors): Gradients w.r.t. the input of the module.
grad_out (tuple of Tensors): Gradients w.r.t. the output of the module.
layer_name (str): Name of the module.
"""
modified_grad = [] # Create a list to store modified gradients
for g in grad_in:
if g is not None:
modified_grad.append(torch.clamp(g, min=0.0)) # Keep only positive gradients
else:
modified_grad.append(None) # Preserve any None values in grad_in
# Save gradients
gradients[layer_name] = modified_grad[0].detach().cpu().numpy().squeeze()
return tuple(modified_grad)We then iterate through all modules in the layer (line 2). If the module is a ReLU activation function, we register the ReLU_hook function (lines 5-11). We use the register_backward_hook function as we want the hook to be used during the backward pass (line 6). When doing this, we use a lambda function as we must also pass the layer's name as a parameter (lines 6-10). If a hook uses only the default parameters, you can simply pass the function's name to the register_backward_hook function.
# Register the hook for all layers
for name, layer in model.named_modules():
# Update the hook for ReLU layers
if isinstance(layer, torch.nn.ReLU):
layer.register_backward_hook(lambda m,
gi,
go,
n=name:
relu_hook(m, gi, go, n))
print(f"Relu hook registered for {name}")Attributions for the target logit
With the hooks in place, we can apply GBP. We'll start by finding the gradients of a target logit w.r.t. the input \(( \frac{\partial y_c}{\partial X} ) \). To do this, we follow the same process as we did for standard backprop (lines 1-13). Except now, during the backward pass (line 13), the ReLU_hook will be applied and only positive gradients will be propagated at the ReLU activation functions. Later, we will also use the gradients it saves to the gradients dictionary.
# Reset gradients
img_tensor = original_img_tensor.clone()
img_tensor.requires_grad_()
model.zero_grad()
# Get the model's prediction (with gradient calculation)
predictions = model(img_tensor)
# Select the class with the highest score
target_class = predictions.argmax()
# Compute gradients w.r.t to logit by performing backward pass
predictions[:, target_class].backward()We get the GBP gradients from the image tensor (line 2). We process them using the ReLU function to remove any negative gradients introduced by the first convolutional layer (line 3). We then plot these alongside the gradients from standard backprop that we got earlier. You can see the result in Figure 3.
# Get the image gradients
grads = img_tensor.grad.detach().cpu().numpy().squeeze()
grads = process_attributions(grads, activation="abs",skew= 0.5, colormap="coolwarm")You'll notice that GBP has produced a much clearer interpretation. Looking at the standard backprop, we may be able to understand important regions of the image. In comparison, with GBP we can see edges and objects that are important. Intuitively, the different foods appear to be contributing to the grocery store prediction.

The above example shows how GBP can be used to explain an individual prediction of the model. That is we can understand which features in the input image are important. This insight can help debug incorrect predictions. We can also go further with GBP to understand the features extracted at the internal layers.
Attributions from intermediate layers
As mentioned, we saved the gradients for intermediate layers obtained during backpropagation. Above we are visualising \(\frac{\partial{y_c}}{\partial X}\) where X is the input. With the intermediate layers, we want to visualise \(\frac{\partial{y_c}}{\partial A}\). That is the gradients of the target logit w.r.t. the activations of a feature map A. Specifically, as we saw in Figure 2, the ReLU_hook saves the modified gradients of the input into the ReLU activation layers. These are the positive gradients passed to previous layers in the network.
The gradients stored at each ReLU layer will have the same number of channels as the kernels in the previous convolutional layer. Going back to the model summary above, we saw that features.0 was a convolutional layer with 64 kernels. This means the gradients saved at features.1, the next ReLU layer, will have 64 channels.
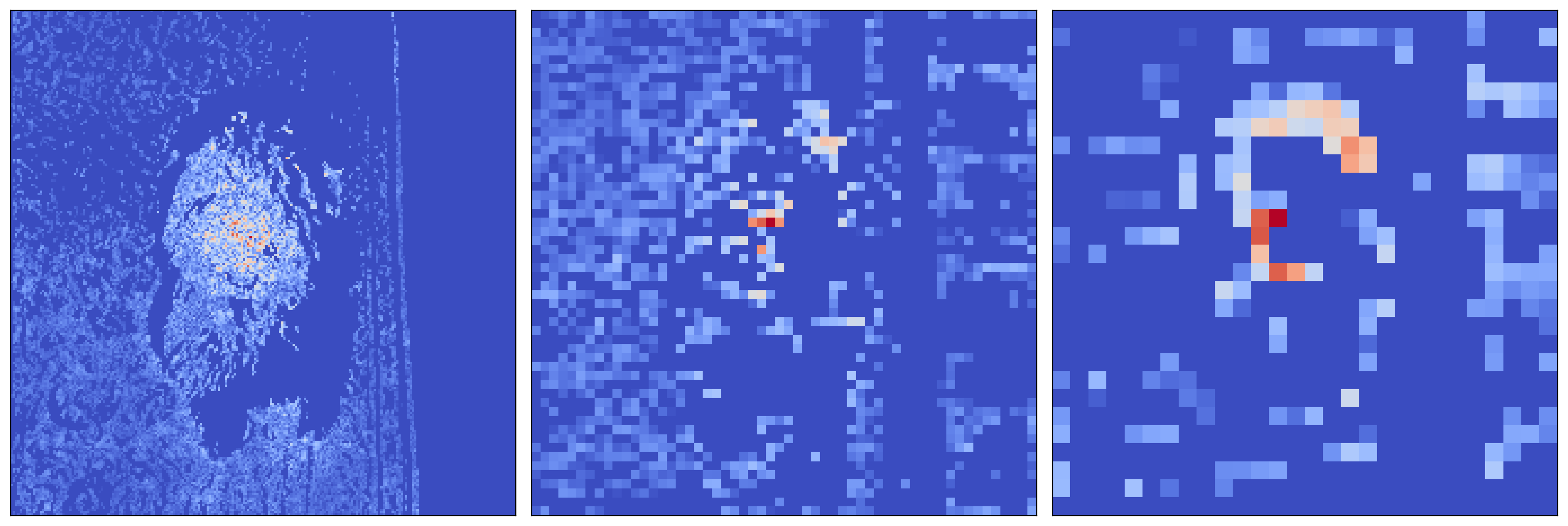
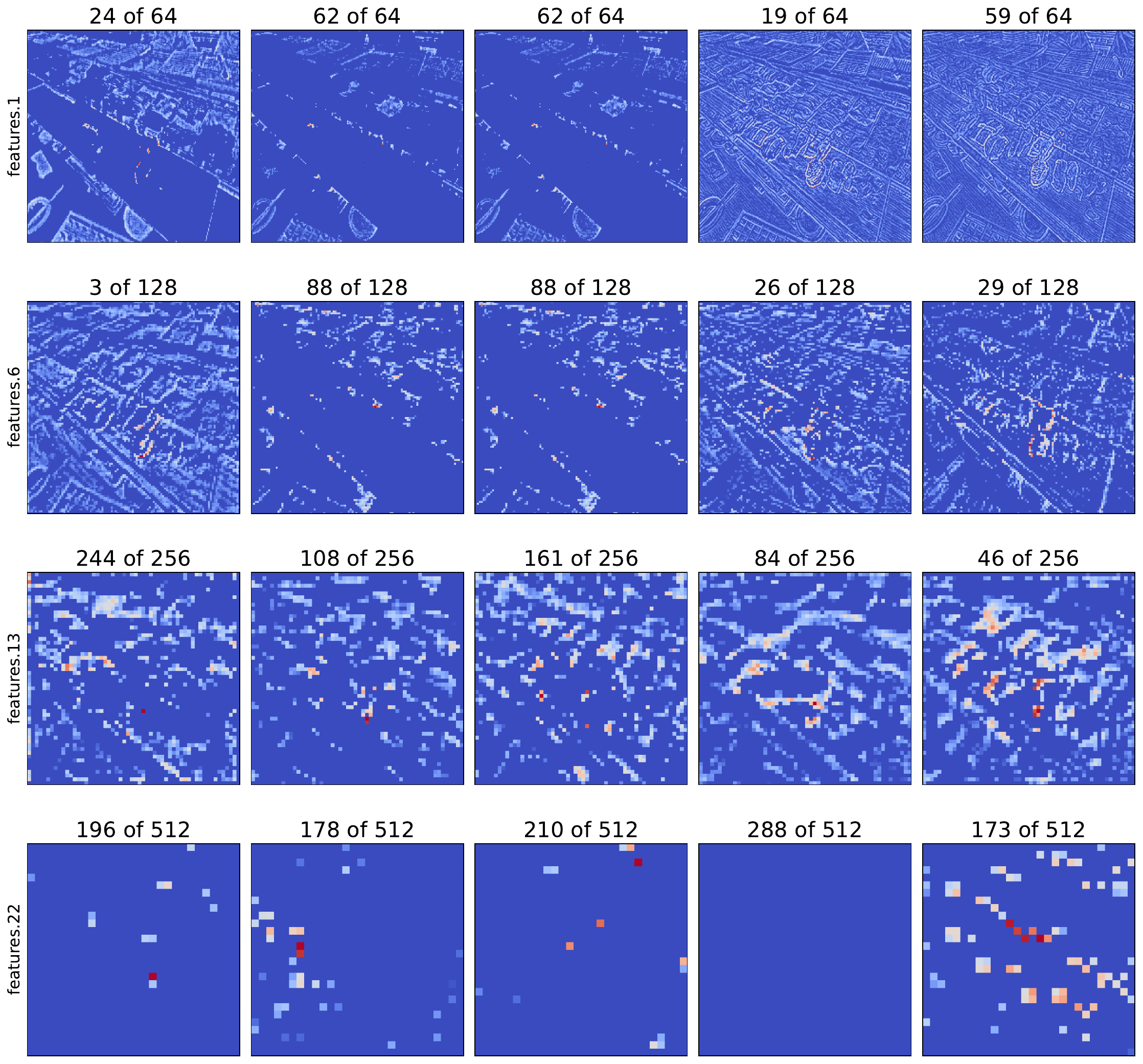
Considering this, we use the code below to visualise some random feature maps from 4 different layers in the network. We start with the first layer and make our way down the network to deeper layers (line 3). When processing the gradients, we do not need to use the ReLU activation (line 12). The gradients will already be positive because of the ReLU_hook. You can see the output in Figure 4.
fig, ax = plt.subplots(4, 5, figsize=(15, 15))
for i,layer in enumerate(['features.1','features.6','features.13','features.22']):
layer_grads = gradients[layer]
print(f"{layer}: {layer_grads.shape}")
for j in range(5):
n_features = layer_grads.shape[0]
r = np.random.randint(0, n_features)
feature_map_grads = layer_grads[r]
feature_map_grads = process_grads(feature_map_grads)
ax[i, j].imshow(feature_map_grads, cmap="coolwarm")
ax[i, j].set_title(f"{r} of {n_features}")
ax[i, j].set_xticks([])
ax[i, j].set_yticks([])
ax[i, 0].set_ylabel(f"{layer}", fontsize=15)
plt.tight_layout()Looking at feature maps like these, we can gain a deeper understanding of how the network works. Like most CNNs, earlier layers detect basic patterns like edges and textures. Deeper layers detect more abstract features like object parts. The deepest layers detect abstract, global features that represent entire objects or semantic meaning. GBP helps in visualising this behaviour by ensuring that only the patterns that positively contributed to the prediction are highlighted.
These kinds of insights go beyond understanding the nature of CNNs. They can actually be used to improve the performance or efficiency of a model. For example, [5] introduced a method called deconvolution, which is the precursor to GBP. They used the approach to visualise the first and second layers of a network, identify problems and adjust the convolutional layer's filter size and stride to correct them.
Going back to the general nature of CNNs, in Figure 4, we can clearly see that spatial information is preserved in earlier layers. That is for features.1 we can see different edges and textures in the same location as the objects in the input image. What is not so obvious is that this spatial information is preserved even in the deeper layers like features.22. We'll prove this using our next approach.
Attributions for activations
Until now, we have visualised gradients for an output logit, \(y_c\). We can also apply GBP to visualise the gradients of the output of any layer in the network. We'll see how by finding the gradients of an element in the feature maps from one of the convolutional layers \(( \frac{\partial y_c}{\partial A_{ij}} )\).
To start, we will need to store the output of all the convolutional layers. To do this, we create a new hook function, act_hook_fn that will store the output of a layer to the activations dictionary. An important difference is we do not detach the output (line 15). We need it to be connected to the computation graph as we will do backward passes starting at different elements in these activations.
# Dictionary to store activations
activations = {}
def act_hook_fn(module, input, output, layer_name):
"""
Hook function to store activations of a layer.
Parameters:
module (nn.Module): The module where the hook is applied.
input (tuple of Tensors): Incoming data to the layer.
output (Tensor): Outgoing data from the layer.
layer_name (str): The name of the layer.
"""
# Store the activations as tensors
activations[layer_name] = output.clone()
print(f"Activation stored for {layer_name}")We apply this hook to every convolutional layer (lines 2-5). If we look back at Figure 1, this means we will be saving the output feature maps from the forward pass. When registering the hook, it is important to now use the register_forward_hook function. This is because we want to save the output from the forward pass.
# Register hooks on all convolutional layers
for name, layer in model.named_modules():
if isinstance(layer, torch.nn.Conv2d):
layer.register_forward_hook(lambda m, i, o, n=name: act_hook_fn(m, i, o, n))
print(f"Forward hook registered for {name}")We make a prediction using our sample image (lines 2-7). This is the forward pass and so the activations for all convolutional layers will be saved.
# Reset gradients
img_tensor = original_img_tensor.clone()
img_tensor.requires_grad_()
model.zero_grad()
# Perform a forward pass
predictions = model(img_tensor)We can see this when we select the activations for the convolutional layer, features.21 (line 2). The shape of the layer is (512, 28, 28). In other words, we have 512 feature maps and each map has 28 by 28 elements.
# Get the activations of the conv layers
layer_act = activations['features.21'][0]
print(layer_act.shape) # (512, 28, 28)We visualise the first 18 feature maps from this layer (lines 4-7). You can see these in Figure 5. Unlike the gradients, these values can be both positive and negative, depending on what features are extracted by each map.
# Plot the activations
fig, ax = plt.subplots(3, 6, figsize=(10, 5))
for i, act in enumerate(layer_act[0:18]):
act_copy = act.clone().detach().cpu().numpy()
act_copy = process_attributions(act_copy,colormap="coolwarm")
ax[i // 6, i % 6].imshow(act_copy)
ax[i // 6, i % 6].set_title(f"{i} of {layer_act.shape[0]}")
ax[i // 6, i % 6].axis("off")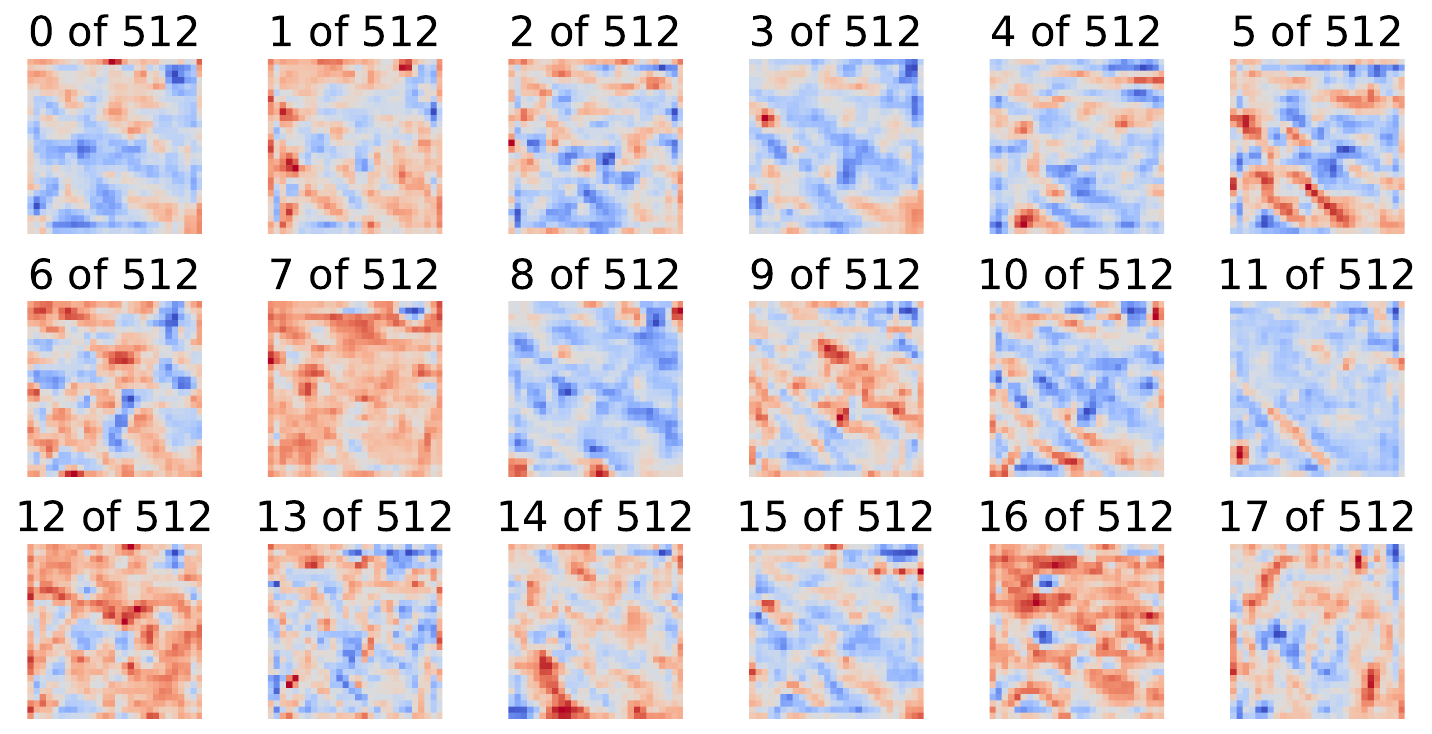
Now let's do a backward pass starting at one of these activations (line 2). Specifically, we have used the element at position (14,14) from the first feature map. This is a point that is roughly in the middle of the (28, 28) map. When we do this, our backwards hook still applies, so only positive gradients are propagated. Although we won't use them, you will also see that the gradients for intermediate layers, starting at this layer, are saved.
# Compute gradients w.r.t element of the activation map
layer_act[0][14,14].backward()We visualise the gradients of the input image like we visualised them for the target logit (lines 2-6). Looking at Figure 6, you can see the features from the input image that are contributing positively to the activation from this element. Before we discuss this further, let's repeat the same process for a few more elements in the feature map.
# Get the gradients of input image
grads = img_tensor.grad.detach().cpu().numpy().squeeze()
grads = process_attributions(grads, activation="abs",skew=0.5)
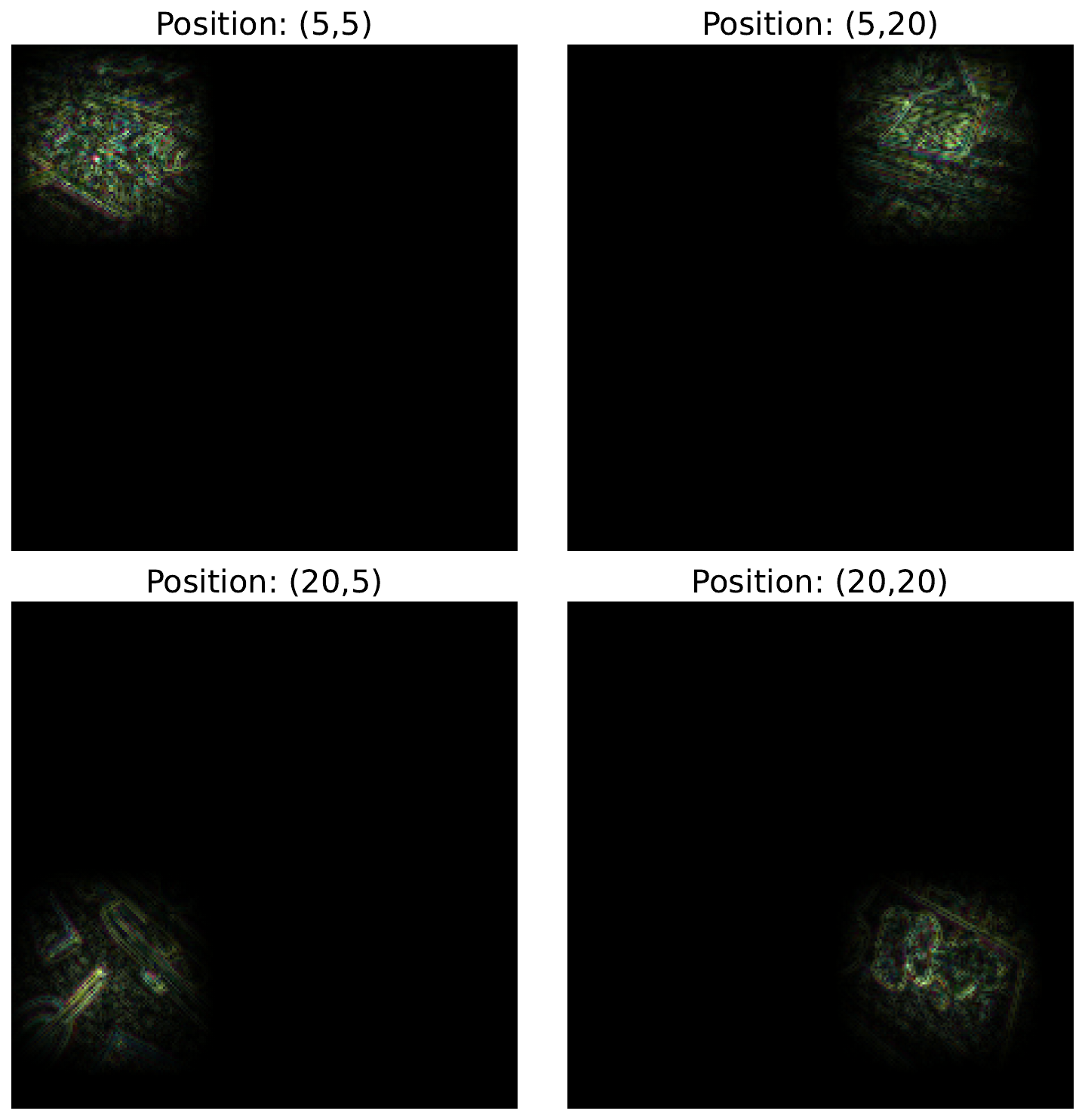
We do this for the positions given on line 1. These give elements from different corners of the feature map. You can see the gradients that contribute to each of these elements in Figure 7.
positions = [(5,5),(5,20),(20,5),(20,20)]
fig,ax = plt.subplots(2,2,figsize=(10,10))
for i, (x,y) in enumerate(positions):
img_tensor = original_img_tensor.clone()
img_tensor.requires_grad_()
model.zero_grad() # Reset gradients
predictions = model(img_tensor)
# Get the activations of the conv layers
layer_act = activations['features.21'][0]
layer_act[0][x,y].backward()
grads = img_tensor.grad.cpu().numpy().squeeze()
grads = process_attributions(grads,activation="abs",skew=0.5)
ax[i // 2, i % 2].imshow(grads)
ax[i // 2, i % 2].set_title(f"Position: ({x},{y})")
ax[i // 2, i % 2].axis("off")Looking at Figure 7, you can see the different objects in the input that have contributed to the activated elements. These are made clear by GBP. Another thing you will have noticed is that the objects are in the same locations as the positions of the elements in the feature map. This demonstrates that, although the deeper feature maps contain more abstract features, they still retain spatial information from earlier layers.
This property of CNNs is why our previous method, Grad-CAM, works so well. Those heatmaps were created by weighting the feature maps of the last convolutional layer in a network. If spatial information was not retained by that layer, then the heatmap would not identify important regions in the input.
GBP goes a long way in reducing noise in saliency maps. As we've seen, this can help explain individual predictions and the general behaviour of a network. Without ReLU masking, the patterns we revealed here would not be as clear. However, there are still cases where GBP goes wrong.
In a later section, we will apply Guided Grad-CAM. It is a method that combines Grad-CAM and GBP to harness the advantages of both methods. The result is even clearer saliency maps that highlight important features.
I hope you enjoyed this article! See the course page for more XAI courses. You can also find me on Bluesky | YouTube | Medium
Additional Resources
- Grad-CAM from Scratch with PyTorch Hooks
- YouTube Playlist: XAI for Tabular Data
- YouTube Playlist: SHAP with Python
Datasets
Conor O’Sullivan, & Soumyabrata Dev. (2024). The Landsat Irish Coastal Segmentation (LICS) Dataset. (CC BY 4.0) https://doi.org/10.5281/zenodo.13742222
Conor O’Sullivan (2024). Pot Plant Dataset. (CC BY 4.0) https://www.kaggle.com/datasets/conorsully1/pot-plants
Conor O'Sullivan (2024). Road Following Car. (CC BY 4.0). https://www.kaggle.com/datasets/conorsully1/road-following-car
References
- Springenberg, Jost Tobias, Dosovitskiy, Alexey, Brox, Thomas, et al. (2014). Striving for simplicity: The all convolutional net. arXiv preprint arXiv:1412.6806.
- Nie, Weili, Zhang, Yang, Patel, Ankit (2018). A theoretical explanation for perplexing behaviors of backpropagation-based visualizations. International conference on machine learning, 3809--3818.
- Adebayo, Julius, Gilmer, Justin, Muelly, Michael, et al. (2018). Sanity checks for saliency maps. Advances in neural information processing systems, 31.
- Yona, Gal, Greenfeld, Daniel (2021). Revisiting sanity checks for saliency maps. arXiv preprint arXiv:2110.14297.
- Zeiler, Matthew D, Fergus, Rob (2014). Visualizing and understanding convolutional networks. European conference on computer vision, 818--833.
Get the paid version of the course. This will give you access to the course eBook, certificate and all the videos ad free.