Like many millennials, I have satisfied my need to nurture something with an unreasonably large pot plant collection. So much so that I have completely lost track of them. In an attempt to remember their names (yes, they have names), I decided to build a machine-learning model.
I started with the four plants you see below — Rudo, Baya, Greg and Yuki. Training this pot plant detector went smoothly, but before I could collect test data, something went horribly wrong…
I dropped Rudo’s pot!
Thankfully, this showed the model was not all it was cracked up to be. After replacing the pot, the model’s accuracy dropped dramatically from 94% on validation data to 70% on test data.
We walk through the process of developing and evaluating this model in the video below. Its goal is two demostrate one of the most important benefits of Explainable AI. That is identifying unknown or hidden bias in machine learning models.
In this article, we will discuss benefit along with 6 others you can see in Figure 1. We will see that XAI can reveal issues with model robustness and accuracy. It allows us to be more certain that our models will not cause any undesired harm. It can even help reduce the complexity of our AI systems. Realistically, these are all crucial problems. Identifying them before deployment can save you a lot of time and money.
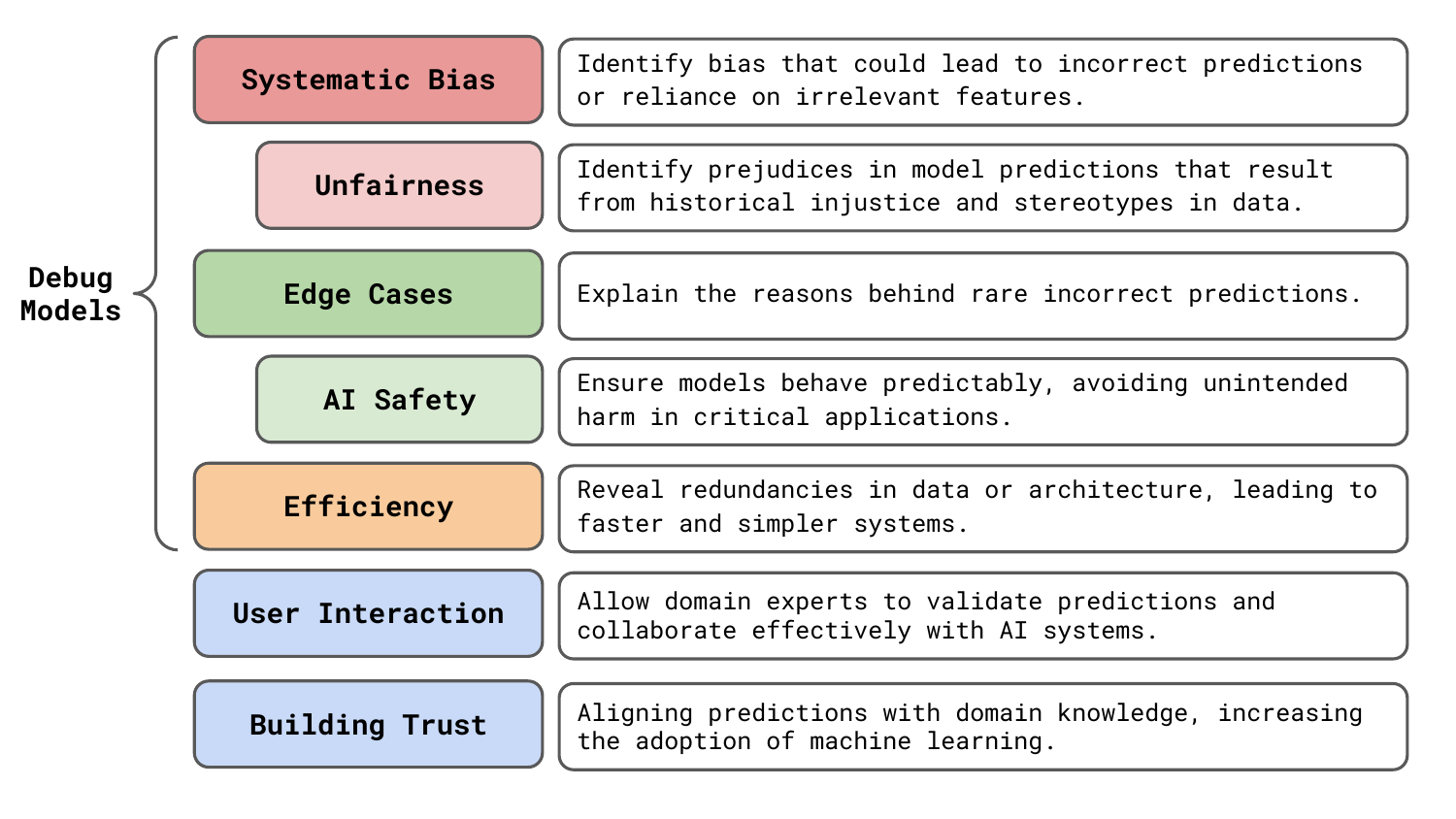
The seven benefits of XAI
When evaluating the Pot Plant detector we discovered something strange. All of the mistakes were coming from Rudo being misclassified as Baya. Something had definitely gone wrong during the model training process. Looking at Figure 2, we can get an idea of what the problem is.

As seen in Figure 3, with the help of an XAI method called Grad-CAM [1], we confirmed the problem. The model was using pixels from the pots to make classifications. In the training set, Baya was always in a blue pot. As Rudo is in a blue pot in the test set, the model is misclassifying it. This is not what we want from a robust plant detector. In short, we have a biased model.
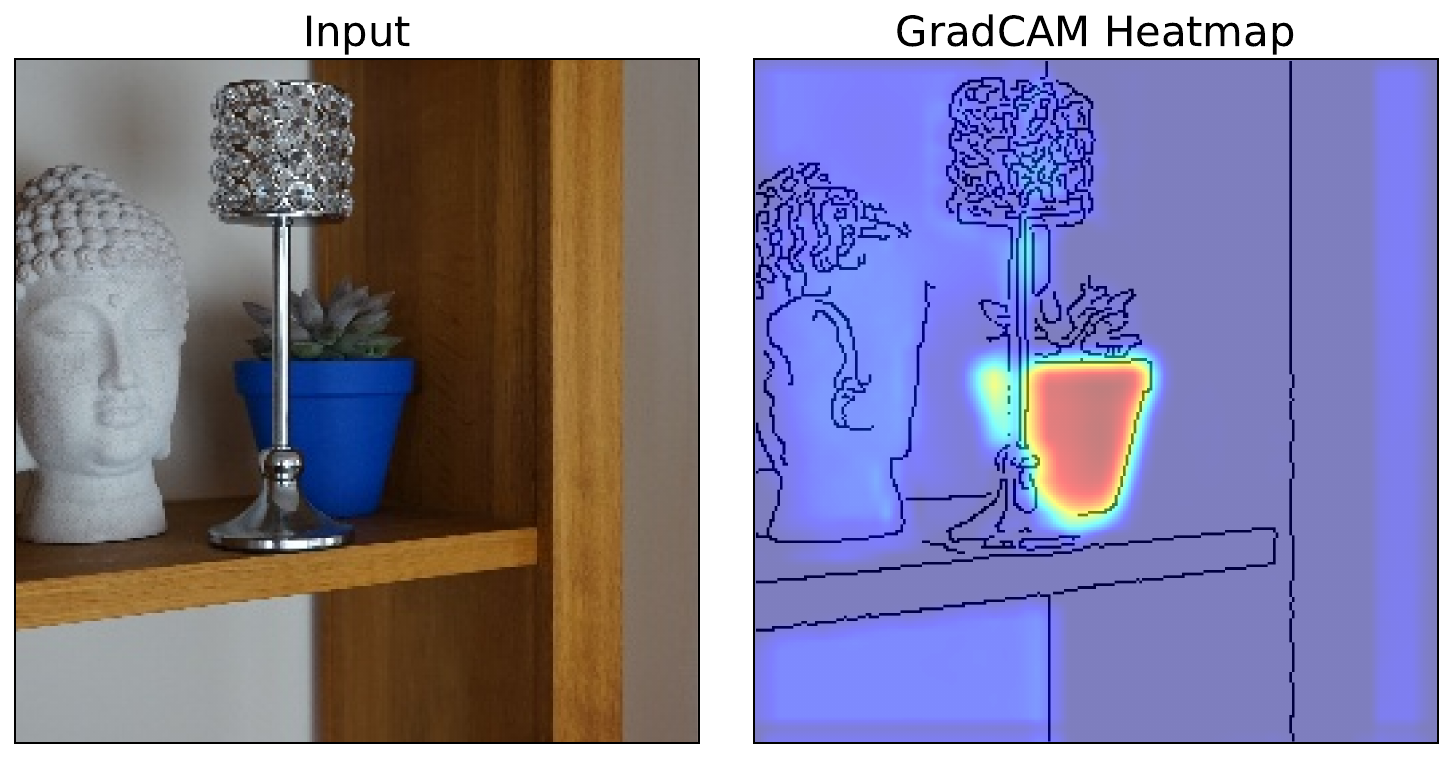
Identifying systematic bias (mistakes) in models
Bias in machine learning is a dynamic term. Here, we refer to bias as any systematic errors that result in the model
- making incorrect predictions or
- making correct predictions but with misleading or irrelevant features
XAI can help explain the first problem but it is with the latter where it becomes particularly important. We refer to this as hidden bias, as it can go undetected by evaluation metrics.
Okay, so for our pot plant detector, we did know there was bias. But this was only after we replaced Rudo's pot. If we hadn't, then the evaluation metrics would have provided similar results for all datasets. This is because the same bias would be present in the training, validation and test sets. That is, regardless of whether the test images were taken independently of the other data.
To a seasoned data scientist, the bias of brightly coloured pots may have been obvious. But, bias is sneaky and can be introduced in many ways. Another example comes from the paper that introduced LIME [2]. The researchers found their model was misclassifying some huskies as wolves. Looking at Figure 4, we see it was making those predictions using background pixels. If the image had snow, the animal was always classified as a wolf.
![raw data and explanation of a bad model’s prediction in the “Husky vs Wolf” task (source: [2]).](https://adataodyssey.com/wp-content/uploads/2026/03/huskey_wolf_wp.png)
The problem is that machine learning models only care about associations. The colour of the pots was associated with the plant. Snow is associated with wolves. Models can latch on to this information to make accurate predictions. This leads to incorrect predictions when that association is absent. The worst-case scenario is when the association is only absent with new data in production. This is what we aim to avoid with XAI.
Identifying unfairness
Unfairness is a special case of systematic bias. This is any error that has led to a model that is prejudiced against one person or group. See Figure 5 for an example. The biased model is making classifications using the person's face/hair. As a result, it will always predict an image of a woman as a nurse. In comparison, the unbiased model uses features that are intrinsic to the classification. These include short sleeves for the nurse and a white coat or stethoscope for the doctor.
![Grad-CAM used to explain a biased model (source: [1]).](https://adataodyssey.com/wp-content/uploads/2026/03/grad_cam_fairness_wp.png)
These kinds of errors occur because historical injustice and stereotypes are reflected in our datasets. Like any association, a model can use these to make predictions. But just like an animal is not a wolf because it is in the snow, a person is not a doctor because they have short hair. And just like any systematic bias, we must identify and correct these types of mistakes. This will ensure that all users are treated fairly and that our AI systems do not perpetuate historical injustice.
Explaining edge cases
Not all incorrect predictions will be systematic. Some will be caused by rare or unusual instances that fall outside the model’s typical experience or training scope. We call these edge cases. An example is shown in Figure 6, where YOLO has falsely detected a truck in the image. The explanation method suggests this is due to "the white rectangular-shaped text on the red poster" [3].
![explanations for a false positive detection (source: [3]).](https://adataodyssey.com/wp-content/uploads/2026/03/incorrect_prediction_explanation_wp.png)
Understanding what causes these edge cases will allow us to make changes to correct them. This could involve collecting more data for the specific scenarios reflected in the edge case. We should also remember that a model exists in a wider AI system. This makes a decision or performs an action based on the prediction from a model. This means some edge cases could be patched with post hoc fixes to how the predictions are used.
Improving AI safety
Correcting edge cases is strongly related to improving the safety of models. In general, ML safety refers to any measure taken to ensure that AI systems do not cause unintended harm to users, society, or the environment. It is about ensuring that our models behave predictably under expected and unexpected conditions. We can be more certain by understanding how models make predictions.
AI safety is always a concern. This is especially true when the systems interact with our physical world. We go from worrying about social media algorithms serving content that harms mental health to systems that can cause physical harm. Think about how accidents involving automated vehicles are always in the news. It is the edge cases, missed by these systems, that lead to loss of human life.
Improving model efficiency
Until now, we have focused on how XAI can improve model performance and robustness. When deploying models, we must take a broader view of performance. We need to consider aspects like the speed and complexity of the entire AI system. In short, we are concerned with the model's resource use. This is referred to as model efficiency.
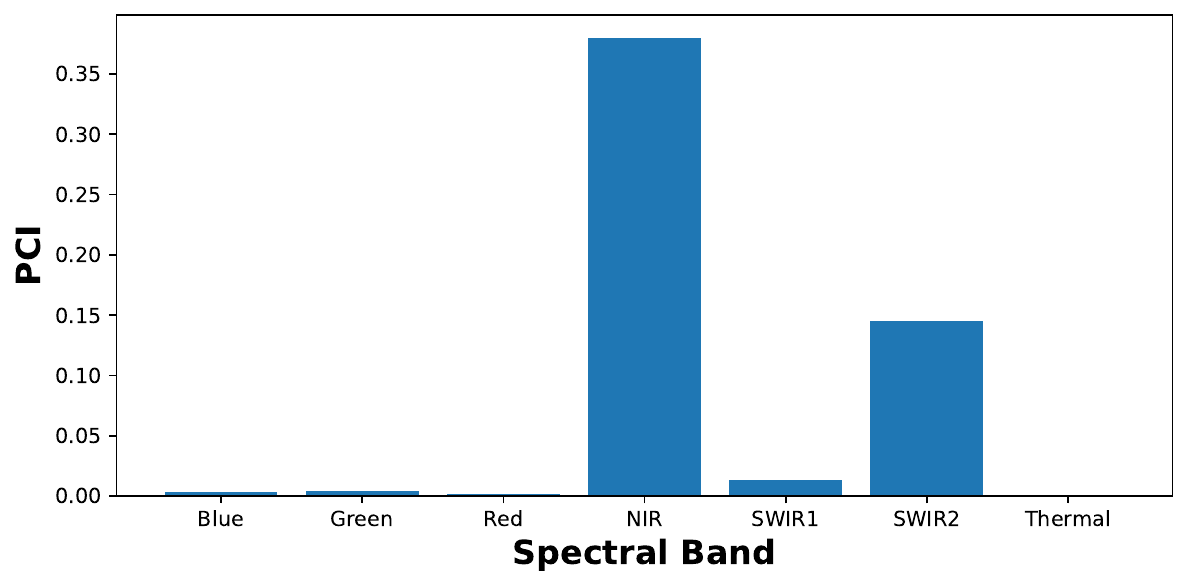
Using XAI, we can learn things that can help improve efficiency. For example, we used Permutation Channel Importance to explain a coastal image segmentation model. Looking at Figure 7, we found that the model was only using 3 of the 12 spectral bands. We could potentially train a model using only these bands and significantly reduce our data requirements.
Another example comes from [4] where a method called deconvolution revealed various issues in a network. This included some “dead” features — filters that never activate for any input. The problems suggested that the model capacity was not being used effectively. To correct this, they redesigned the architecture by adjusting filter sizes, increasing depth, and optimising stride and pooling. The result was a network with more discriminative features, and the improved architecture even achieved higher ImageNet classification accuracy than the previous state-of-the-art.
These kinds of insights can be used in future model builds to improve model efficiency. By only including data needed for accurate predictions, we can significantly cut down data processing time and storage space. Simpler input features and architecture will all provide faster predictions. On the other hand, we could improve accuracy while maintaining a similar model size.
The benefits we've mentioned up until now can all be summarised as debugging or improving a model. We want to identify any mistakes or inefficiencies. This is to improve the performance, reliability, fairness and safety of the resulting AI systems. The next benefits are different. They are more about the humans who interact with the models.
Enhancing user interaction
For many applications, XAI is necessary to provide more actionable information. For example, a medical image model can make a classification (i.e. a diagnosis). Yet, on its own, this has limited benefits. A patient would likely demand reasons for a diagnosis. It also does not provide any information on how severe the condition is or how it could best be treated.
Looking at Figure 8, you can see how the pixels that contributed to the positive diagnosis have been highlighted. Along with the classification, this provides more actionable information. That is, the doctor can confirm the classification, explain where and how severe the tumour is and begin to understand the best course of action.
![Grad-CAM visualisation showing the areas of the brain that have contributed to positive tumour diagnosis (source: [5]).](https://adataodyssey.com/wp-content/uploads/2026/03/grad_cam_brain_tumor_wp.png)
In general, XAI can help us make use of machine learning in industries where it is too risky to fully automate a task. Using the output of XAI, a professional can apply their domain knowledge to ensure a prediction is made in a logical way. The output can also tell us how to best go about addressing a prediction. Ultimately, through this type of interaction, we enable better human-machine collaboration.
Building trust in models
Even for applications that could be fully automated, XAI can help increase adoption. Machine learning has the potential to replace processes in finance, law or even farming. Yet, you would not expect your average farmer or lawyer to have an understanding of neural networks. Their black-box nature could make it difficult for them to accept predictions. Even in more technical fields, there can be mistrust of deep learning methods.
XAI can be a bridge between computer science and other industries or scientific fields. It allows you to relate the trends captured by a model to the domain knowledge of professionals. We can go from explaining how correct the model is to why it is correct. If these reasons are consistent with their experience, a professional will be more likely to accept the model's results.
Ultimately, when stakeholders understand the reasoning behind model predictions, it is easier to secure buy-in for AI solutions. This is particularly true in sensitive environments. In fact, as the world becomes more critical of AI and introduces more regulations, XAI will become necessary to meet legal and ethical requirements.
So hopefully you are convinced. XAI can help you identify and explain systematic biases and edge cases in your models. Its insights can not only improve performance but also the efficiency, fairness and safety of your AI systems. Through building trust and improving interactions, it can even increase the adoption of machine learning.
I hope you enjoyed this article! See the course page for more XAI courses. You can also find me on Bluesky | YouTube | Medium
Additional Resources
- Article: The 6 Benefits of XAI (focused on tabular data)
- Article: Get more out of XAI: 10 Tips
- YouTube Playlist: XAI for Tabular Data
- YouTube Playlist: SHAP with Python
Datasets
Conor O’Sullivan, & Soumyabrata Dev. (2024). The Landsat Irish Coastal Segmentation (LICS) Dataset. (CC BY 4.0) https://doi.org/10.5281/zenodo.13742222
Conor O’Sullivan (2024). Pot Plant Dataset. (CC BY 4.0) https://www.kaggle.com/datasets/conorsully1/pot-plants
Conor O'Sullivan (2024). Road Following Car. (CC BY 4.0). https://www.kaggle.com/datasets/conorsully1/road-following-car
References
- Selvaraju, Ramprasaath R, Cogswell, Michael, Das, Abhishek, et al. (2017). Grad-cam: Visual explanations from deep networks via gradient-based localization. Proceedings of the IEEE international conference on computer vision, 618--626.
- Ribeiro, Marco Tulio, Singh, Sameer, Guestrin, Carlos (2016). Why should i trust you? Explaining the predictions of any classifier. Proceedings of the 22nd ACM SIGKDD international conference on knowledge discovery and data mining, 1135--1144.
- Kirchknopf, Armin, Slijepcevic, Djordje, Wunderlich, Ilkay, et al. (2022). Explaining yolo: leveraging grad-cam to explain object detections. arXiv preprint arXiv:2211.12108.
- Zeiler, Matthew D, Fergus, Rob (2014). Visualizing and understanding convolutional networks. European conference on computer vision, 818--833.
- T. R, Mahesh, V, Vinoth Kumar, Guluwadi, Suresh (2024). Enhancing brain tumor detection in MRI images through explainable AI using Grad-CAM with Resnet 50. BMC Medical Imaging, 24(1), 107.
Get the paid version of the course. This will give you access to the course eBook, certificate and all the videos ad free.